Fungsi Plot: Model Linier, KDE, dan Map
Melalui kelas ini, kamu diajak untuk:
- Mengenal lm, KDE, dan Map dan bar chart untuk visualisasi data.
- Mengetahui susunan kode dan parameter untuk mengatur lm, KDE, dan Map.
Pengantar
Di materi sebelumnya, kita telah mengulas jenis grafik berbentuk batang, seperti histogram dan bar chart. Keduanya adalah visualisasi yang dinilai cukup sederhana. Kali ini, kita akan menyelami jenis-jenis grafik yang lebih kompleks, yaitu regresi, KDE, dan map atau peta.
Visualisasi Regresi dengan Model Linier
Regresi adalah salah satu analisis statistik mengenai persebaran data berdasarkan variabel dependen dan independen. Regresi biasa digunakan untuk melihat tren, mengukur korelasi dan pengaruh, serta membuat prediksi.
Visualisasi regresi dalam Seaborn biasa menggunakan lm atau lmplot. Fungsi yang digunakan adalah lmplot(). Untuk menggunakan lmplot(), kita perlu memasukkan variabel x (independen) dan variabel y (dependen) ke dalam parameter.
Misal kita ingin melihat persebaran data total tagihan dan tips. Lihat susunan kode di bawah ini.
df = sns.load_dataset("tips")
sns.lmplot(data=df, x="total_bill", y="tip")Tampilannya:
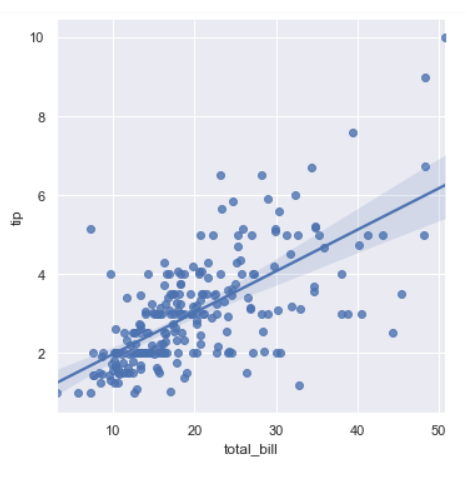
Kita dapat menggunakan parameter-parameter tambahan dengan hue=”” dan kolom atau col=””. Misal kita ingin visualisasi yang lebih kompleks dengan menambahkan data pembanding, seperti hari dan waktu.
sns.lmplot(data=df, x="total_bill", y="tip", hue="time", col="day", col_wrap=2)Tampilannya:
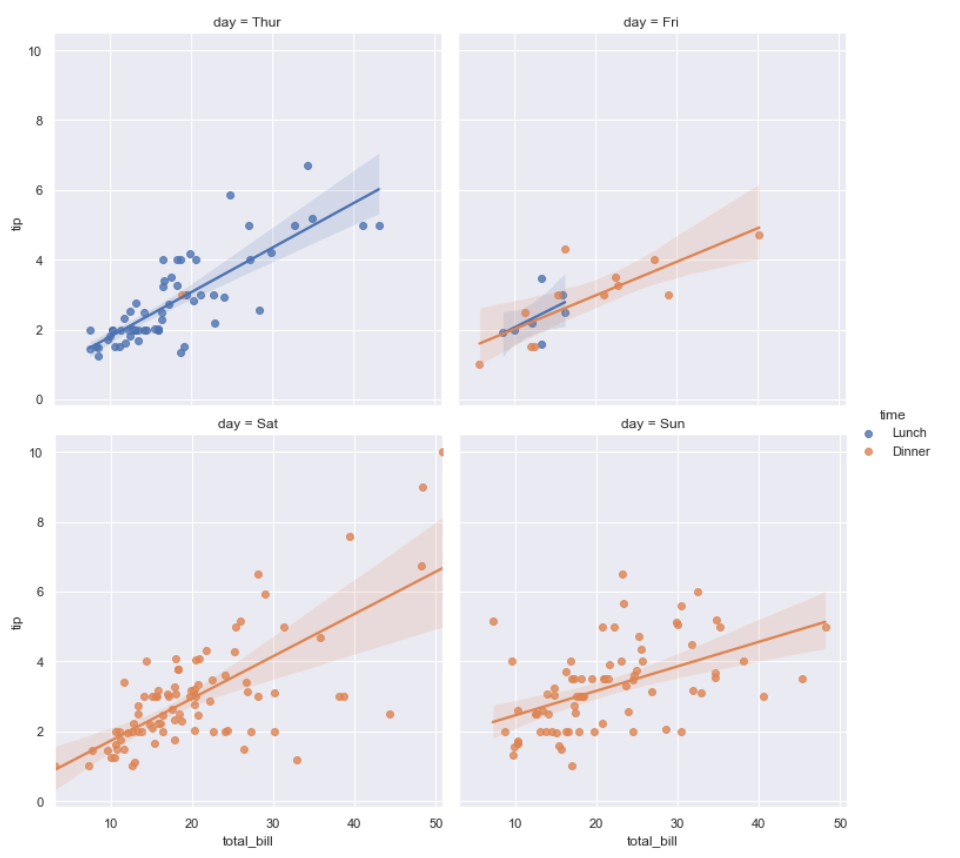
Kepadatan dengan KDE
KDE adalah singkatan dari Kernel Density Estimate, digunakan untuk memvisualisasikan kepadatan probabilitas dari variabel data kontinu. Kita dapat menggunakan KDE untuk memplot banyak variabel (univariat) sekaligus.
Sekarang mari buka dataset baru, yaitu data mengenai penguin.
df = sns.load_dataset("penguins")
df.head()Data yang akan muncul seperti berikut:
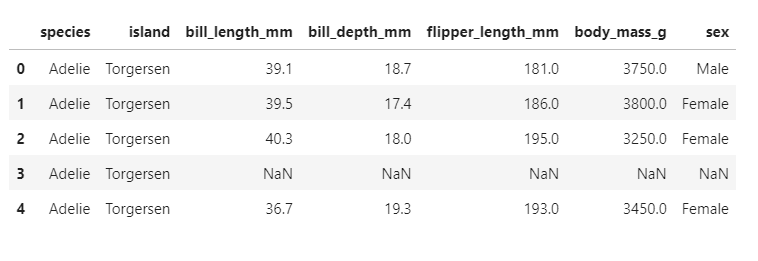
Misal kita ingin melihat plot KDE dari panjang sirip penguin berdasarkan spesiesnya. Dari data penguin, terdapat tiga spesies, yaitu Adelie, Chinstrap, dan Gentoo. Maka kita akan memasukkan ketiga spesies tersebut sebagai variabel.
sns.kdeplot(df.loc[(df["species"]=="Adelie"),
"flipper_length_mm"], color="r", shade=True, label="Adelie")
sns.kdeplot(df.loc[(df["species"]=="Chinstrap"),
"flipper_length_mm"], color="g", shade=True, label="Chinstrap")
sns.kdeplot(df.loc[(df["species"]=="Gentoo"),
"flipper_length_mm"], color="b", shade=True, label="Gentoo")Tampilannya:
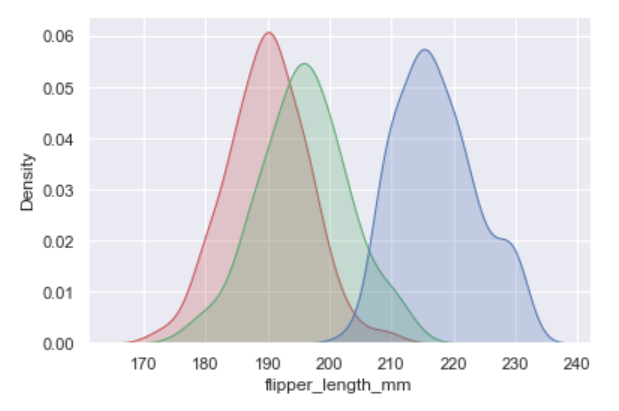
Heatmap
Heatmap adalah bentuk visualisasi map pertama yang akan kita ulas. Heatmap berisi grafik dua dimensi dari data yang direpresentasikan oleh warna. Heatmap menggunakan fungsi heatmap().
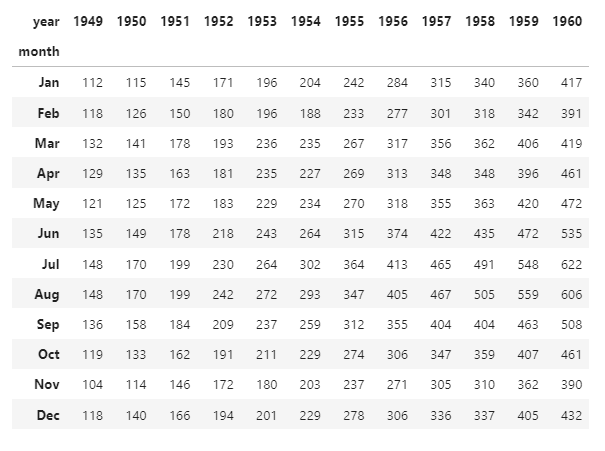
Sebagai ilustrasi, kita akan menggunakan data penerbangan. Dalam data ini, ada jumlah penumpang dari tahun 1949-1960 serta angka setiap bulannya. Mari muat data tersebut dalam Python.
df = sns.load_dataset("flights")Untuk menggunakan heatmap, kita perlu merapikan susunan tabel dengan fungsi pivot(). Dalam fungsi tersebut, isi parameter berdasarkan indeks. Lihat susunan kode di bawah ini.
df = sns.load_dataset("flights").pivot("month", "year", "passengers")Kode di atas akan menampilkan visualisasi berikut:
Sekarang, saatnya gunakan fungsi heatmap() untuk membuat visualisasi.
# linewidth adalah lebar garis, cmap adalah palet warna
sns.heatmap(df, linewidths = 1, cmap = "GnBu")Tampilannya:
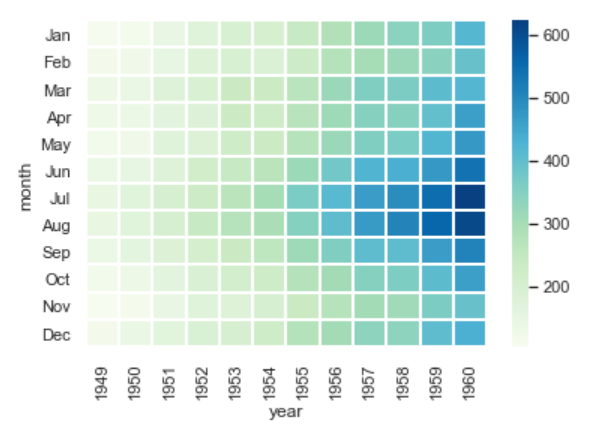
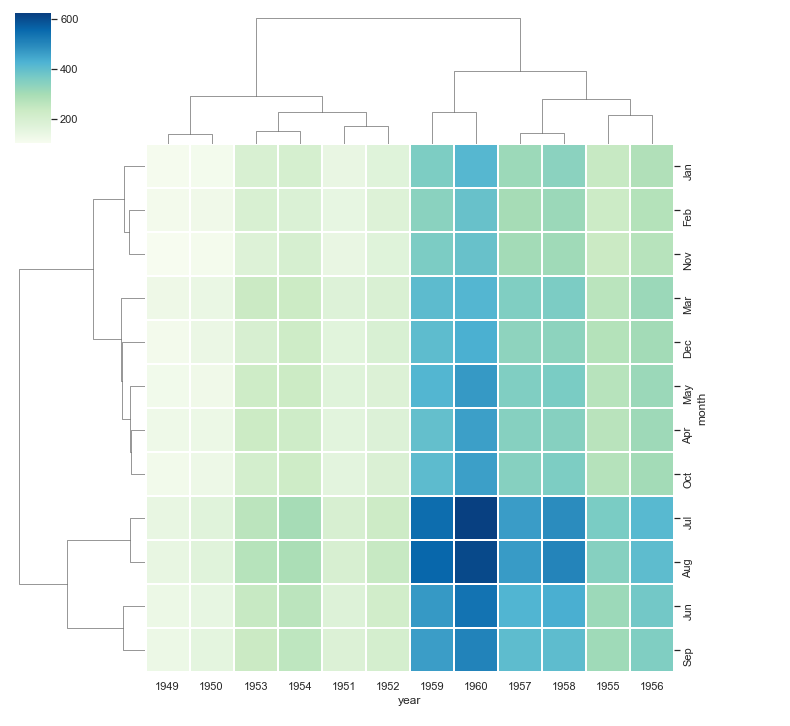
Cluster Map
Sama seperti heatmap, cluster map juga dibedakan berdasarkan warna. Bedanya, cluster map memplot dataset sebagai heatmap yang dikelompokkan secara hirarkis.
Dengan dataset yang sama, mari lihat perbedaan visualisasi cluster map dan heatmap.
df = sns.load_dataset("flights").pivot("month", "year", "passengers")
sns.clustermap(df, linewidths = 1, cmap = "GnBu")Tampilannya:
Pro Tips
- Model linier adalah visualisasi yang digunakan untuk analisis regresi linier dengan variabel independen dan dependen sebagai parameter.
- KDE digunakan untuk membuat visualisasi kepadatan probabilitas dari variabel data kontinu dan non-parametrik.
- Heatmap digunakan untuk memvisualisasikan grafik dua dimensi berdasarkan intensitas warna, sementara cluster map adalah plot dataset berdasarkan heatmap yang dikelompokkan secara hirarkis.
Kuis
Dalam regresi linier, apa simbol representasi dari variabel independen?