Melatih Machine Learning dengan Kumpulan Data
Melalui kelas ini, kamu diajak untuk:
- Mengidentifikasi langkah-langkah mengelola dataset untuk dilatih.
- Mengetahui cara menerapkan metode train/test split untuk melatih data.
Mengapa Harus Dilatih?
Machine learning bekerja layaknya otak manusia. Kita tak langsung pintar. Setiap dari kita berproses dengan pengetahuan baru dari kecil hingga dewasa. Setiap kebaruan yang masuk ke otak diolah. Penalarannya tak selalu sukses, tapi kegagalan mempertajam nalar.
Seperti otak manusia yang tak langsung pintar, machine learning membutuhkan tempaan berupa pemrosesan berbagai jenis data. Kumpulan data layaknya informasi yang diproses manusia. Membesarkan machine learning sama seperti membesarkan manusia.
Mengimpor Library
Pertama-tama, kita perlu mengimpor modul atau library pendukung untuk melakukan klasifikasi. Rangkaian library ini meliputi:
- Pandas untuk mengelola dataset.
- Matplotlib untuk visualisasi data.
- Seaborn untuk visualisasi data.
- Train/Test Split untuk melatih data.
Lihat susunan kode di bawah ini.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_splitMengelola Dataset
Setelah modul-modul berhasil diimpor, kita dapat mengelola dataset. Langkah pertama yang perlu dilakukan adalah memuat dataset. Pada materi kali ini, kita akan menggunakan dataset penguin dan fitur-fitur yang dimilikinya.
Lihat susunan kode di bawah ini.
penguins_df = pd.read_csv("penguins.csv")
print(penguins_df) 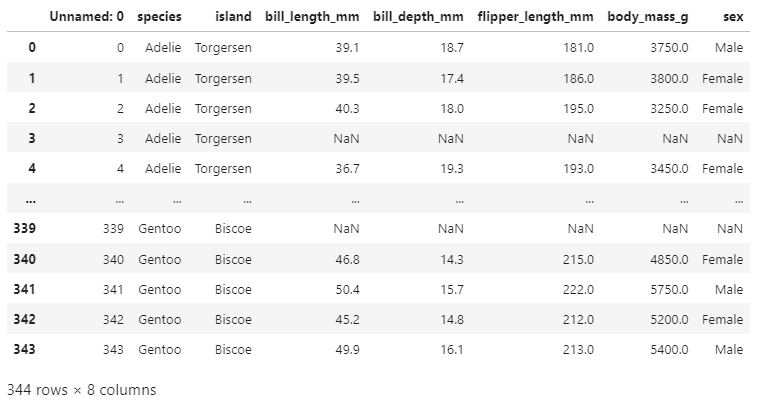
Label yang akan kita gunakan pada kasus ini adalah label spesies. Mari lihat apa saja spesies yang ada dalam dataset.
[in]:
print(penguins_df["species"].unique())
[out]:
['Adelie' 'Chinstrap' 'Gentoo']Menghapus kategori selain label spesies
Kita hanya akan mengelola data-data numerik berdasarkan label spesies. Maka dari itu, kita mungkin ingin menghapus kategori selain spesies untuk memudahkan kita melihat dataset.
penguins_df = penguins_df.drop("Unnamed: 0", axis=1)
penguins_df = penguins_df.drop("island", axis=1)
penguins_df = penguins_df.drop("sex", axis=1)Mengelola nilai data NaN
Dari tampilan dataset penguin, masih ada nilai NaN pada baris-baris data. NaN ini disebut sebagai missing value. Missing value dapat mengganggu proses klasifikasi. Maka dari itu, kita perlu mengelola nilai ini dengan fungsi dropna().
penguins_df = penguins_df.dropna() Visualisasi Data
Selanjutnya, buat visualisasi data untuk mempermudah kita melihat persebaran data fitur-fitur penguin berdasarkan label spesies. Untuk visualisasi data, kita menggunakan seaborn pairplot().
Lihat susunan kode di bawah ini.
# style background grafik
sns.set_style("darkgrid")
# fungsi pairplot() berisi KDE dan scatterplot
sns.pairplot(penguins_df, hue = "species", diag_kind = "kde", kind = "scatter", palette = "husl")
# fungsi menampilkan grafik
plt.show()Berikut tampilannya
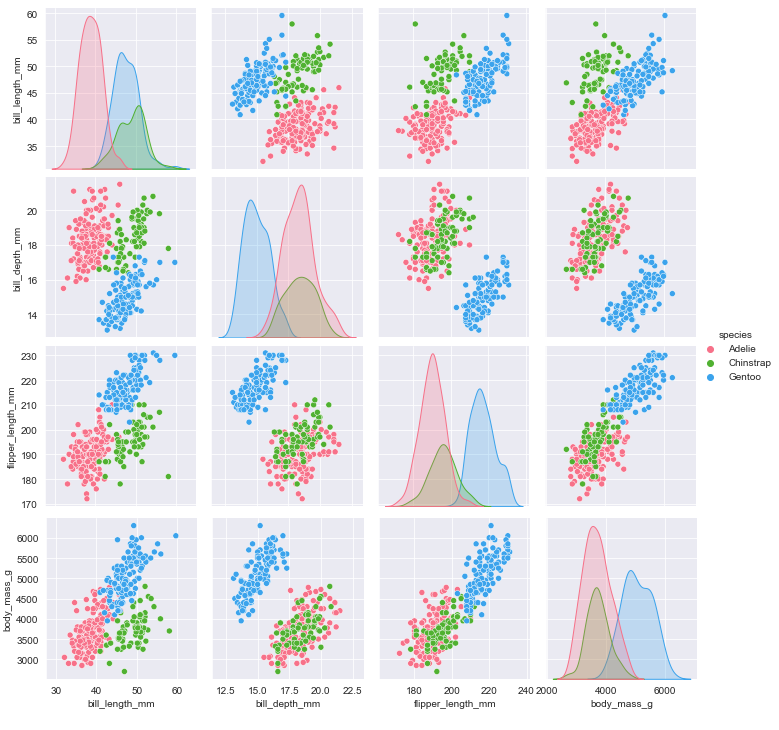
Melatih Data
Sekarang kita tiba di bagian pelatihan data. Kali ini, kita akan menggunakan metode train/test split. Metode ini membagi dataset menjadi dua bagian, train dan test. Train akan digunakan dalam fit model machine learning, sementara test digunakan untuk evaluasi hasil fit model.
Lihat susunan kode di bawah ini.
# deklarasi y sebagai label
y = penguins_df["species"]
# deklarasi X untuk dataset tanpa label
X = penguins_df.drop("species", axis=1)
# penerapan train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01, random_state=202020)Dari susunan kode di atas, ada parameter-parameter yang perlu dimasukkan ke dalam fungsi train_test_split().
Ketuk untuk mengetahui fungsi masing-masing parameter.
X dan y
Merujuk pada dataset yang akan digunakan.
test_size
Menentukan ukuran pengujian dataset. Nilai defaultnya adalah 0.25.
Random_state
mode default untuk melakukan split acak. Parameter ini menggunakan fungsi np.random(). Kita dapat mengisi angka secara acak.
Jika kita memanggil X_test, kita akan mendapatkan dataset seperti ini:
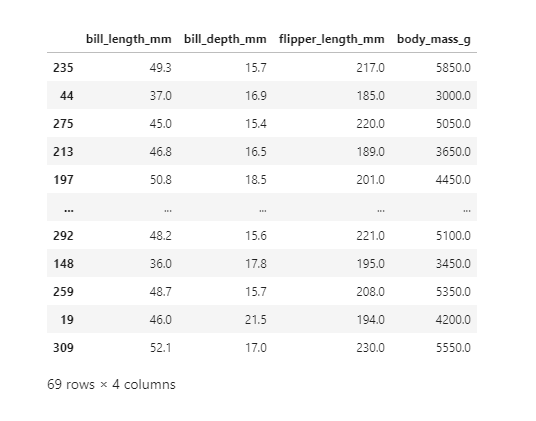
Dari tampilan dataset tersebut, dapat dilihat bahwa ada 69 baris tanpa label. Dataset ini yang nantinya akan diprediksi menggunakan model klasifikasi.
Pro Tips
- Sebelum melatih data, kita perlu mengelola data dengan membersihkan label kategori yang tak diperlukan dan mengatasi missing value.
- Train/test split adalah salah satu metode pelatihan data dengan memisahkan dua jenis data, train untuk fit model dan test untuk evaluasi hasil fit model.
Kuis
Apa yang bukan parameter wajib dalam fungsi train_test_split()?